Товары по запросу: "brown corpus frequency list"
В категории "Петли и механизмы" такого товара не найдено
Чаще всего в данной категории ищут:
- мебельная петля угловая 45 градусов
- петля мебельная со смещением
- петля дверная нержавеющая сталь усиленная
- вкладная петля 180
- дверная петля dhv
- петля обычная мебельная
- lemax петля мебельная
- заглушки hafele для петель
- заглушки для петель окна
- механизмы вертикального открывания фасадов
- накладка на фасад
- накладки для мебельных петель
- петля вкладная 26мм
- петля мебельная с доводчиком для стеклянной двери
- дверная петля palladium n 500
- накладка под петлю мебельную
- заглушки для петлей пластиковых дверей
- купить дверную петлю archie
- петля дверная нержавейка
- мебельный подъемный механизм для фасадов
Фотоальбом:
Word frequency lists (in corpus linguistics)

Frequency distributions of different specifity classes in the Brown

Relative frequencies of actually and in fact in the Brown Corpus

CoRD
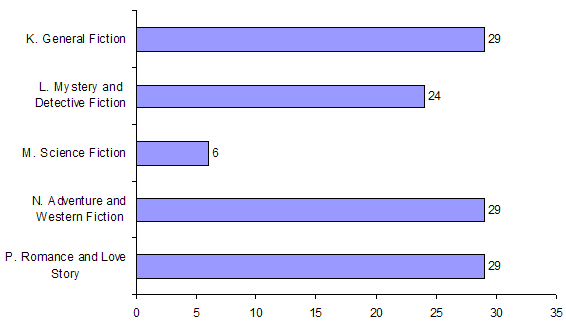
Brown Corpus

Corpus frequency as referents and names and the selection of categories

LING/C SC 581: Advanced Computational Linguistics

Some dispersion values for four words in the Brown corpus

Комментарии:
Brown Corpus
The Brown University Standard Corpus of Present-Day American English, better known as simply the Brown Corpus, is an electronic collection of text samples of American English, the first major structured corpus of varied genres. This corpus first set the bar for the scientific study of the frequency and distribution of word categories in everyday language use.
BROWN Corpus search online
The Brown corpus (full name Brown University Standard Corpus of Present-Day American English) was the first text corpus of American English. The original corpus was published in 1963-1964 by W. Nelson Francis and Henry Kučera (Department of Linguistics, Brown University Providence, Rhode Island, USA). The corpus consists of 1 million words ...
Brown Corpus Manual
Brown Corpus Manual. BROWN CORPUS MAUNAL. MANUAL OF INFORMATION to accompany A Standard Corpus of Present-Day Edited American English, for use with Digital Computers. by W. N. Francis H. Kucera Brown University Providence, Rhode Island Department of Linguistics Brown University 1964 Revised 1971 Revised and Amplified 1979.
Laurence Anthony's AntConc
Brown Corpus frequency lists. Brown Corpus word frequency list (lowercase) Brown Corpus word frequency list (mixed case) Lemma lists. Lemma lists. These lists can be imported into AntConc (3.5.9 and earlier) to create lemma word lists. From AntConc 4.0, it is recommended that you Part-Of-Speech (POS) tag and lemmatize your files, e.g. using ...
Python Tutorial 4: Tokenization, Lemmatization, and Frequency Lists
In this section, we will create a lemmatized frequency list for the Brown corpus. To do so, we will write a function that: Finds all relevant files in a folder (i.e., all of our corpus documents) Reads each file; Tokenizes each file; Lemmatizes each file; Calculates frequency figures for the entire corpus_list; Returns a frequency dictionary
BrownStats : Basic statistics of texts in the Brown corpus
corpora_package: corpora: Statistical Inference from Corpus Frequency Data; corpora_palette: Colour palettes for linguistic visualization ... This data set provides some basic quantiative measures for all texts in the Brown corpus of written American English (Francis & Kucera 1964), Usage BrownStats Format. A data frame with 500 rows and the ...
CoRD
The Brown Corpus was the first computer-readable general corpus of texts prepared for linguistic research on modern English. It was compiled by W. Nelson Francis and Henry Kučera at Brown University in the 1960s and contains of over 1 million words (500 samples of 2000+ words each) of running text of edited English prose printed in the United ...
Word & Frequency Lists
Russian Frequency List (by Serge Sharoff) based on a corpus of modern Russian fiction and political texts (more than 35 million words). The list includes about 33000 words which frequency is greater than 1 ipm (instances per million words). A shorter selection of 5000 most frequent words is also available. The list provides word rank, frequency ...
CoRD
Basic structure. (Source: the Brown Corpus manual) The Corpus is divided into 500 samples of 2000+ words each. Each sample begins at the beginning of a sentence but not necessarily of a paragraph or other larger division, and each ends at the first sentence ending after 2000 words. The samples represent a wide range of styles and varieties of ...
How to find adjective frequency from a specific categories in brown
from collections import Counter from nltk.corpus import brown # Split the words and POS tags words, poss = zip(*brown.tagged_words()) # Put them into a Counter object pos_freq = Counter(poss) for pos in pos_freq: print pos, pos_freq[pos]